
動作環境
- Python 3.9.2
- pip 21.3.1
- macOS 12.0.1
一休の口コミをPythonでスクレイピングしてCSVファイルとして取得する方法をまとめています。
以前、「じゃらんの口コミをスクレイピングしてみる」という記事で、Jupyter NotebookというPythonなどをWebブラウザ上で記述・実行できる統合開発環境を使ってスクレイピングを実行したので、今回もJupyter Notebookを使って解説いたします。
Pythonのバージョン確認方法やJupyter Notebookのインストール方法は以前のこちらの記事に手順をまとめておりますので、環境の構築方法などはこちらの記事をご確認ください。

じゃらんの口コミのスクレイピングでは、Pythonのライブラリ「Beautiful Soup」を使用しましたが、今回は「Selenium」を使ってブラウザを自動操作してスクレイピングを行なっていきます。
BeautifulSoupとSeleniumの違い
Beautiful Soup・・・HTMLやXMLファイルからデータを取得できる、WEBスクレイピングなどに使われるPythonのライブラリの一つ。
Selenium・・・Google ChromeやFirefoxなどのブラウザ操作を自動化するPythonのライブラリです。タスクの自動化やスクレイピング、Webサイトのクローリングなど様々な用途で利用されています。
なぜ「Beautiful Soup」ではなく「Selenium」でスクレイピングを行うのか?
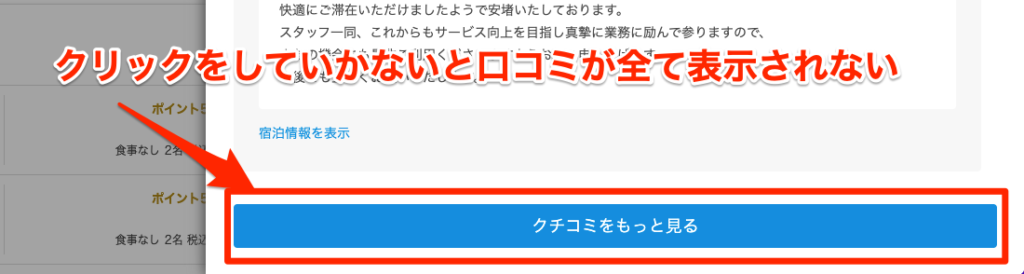
今回、「Beautiful Soup」ではなく「Selenium」でスクレイピングを行う理由は、一休の口コミはじゃらんと違ってJavaScriptに制御されたボタンをクリックすることで口コミが書かれた要素が現れるという仕様になっているため、Beautiful SoupでHTMLデータを取得してもボタンに隠れた要素を取得することができないためです。
そのため、「Selenium」を使ってブラウザを操作しボタンをクリックするという動作を行うことで口コミデータを取得する必要があります。
seleniumをインストールする
$ pip install seleniumwebdriver_managerをインストールする
$ pip install webdriver_managerJupyter Notebookを起動する
$ python3 -m notebookコードを記述&実行
今回はこちらのページの口コミを取得します。
https://www.ikyu.com/00000662/#review-modal
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
from webdriver_manager.chrome import ChromeDriverManager
import pandas
import time
options = Options()
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
url = 'https://www.ikyu.com/00000662/#review-modal'
driver.get(url)
# 「口コミをもっと見る」のボタンがなくなるまでクリックを続ける
while True:
try:
element = driver.find_element_by_css_selector('.WordOfMouth-ikyu__showMore--21ctT')
time.sleep(1)
if element.is_displayed():
element.click()
else:
break
except NoSuchElementException:
# これ以上読み込めなくても終了
break
body = driver.find_elements_by_xpath("//dd[@class='WordOfMouth-ikyu__reviewContentsFusuma--TZ3NI']/p[1]")
date = driver.find_elements_by_class_name('WordOfMouth-ikyu__postedDate--1YawZ')
l=[]
for d, b,in zip(date, body):
data={}
data["口コミ"]=b.text
data["投稿日"]=d.text
l.append(data)
# ドライバーを終了させる
driver.quit()
df=pandas.DataFrame(l)
df.to_csv("一休.csv", encoding='utf_8_sig')
df実行後、ディレクトリ配下に「一休.csv」が出来ていればOKです。
解説
webdriverでChromeを起動後URLにアクセスします。その後、While文でループを回して「口コミをもっと見る」のボタンを自動でクリックしていき口コミを全て表示しています。
is_displayed() で要素のstyle属性が非表示になっているか(「口コミをもっと見る」のボタンが非表示になっているか)を判定して、ボタンの要素が非表示になりこれ以上ボタンを押せなくなっている状態であればループ処理を抜けるようにしています。
ボタンをクリックするループを抜けると全ての口コミが表示されている状態でページが表示されているので、ここで初めて口コミの要素を取得し、ループを回して情報をデータ化しています。
CentOS7上の本番環境ではエラーが出てGoogle Chromeが起動しない
CentOS上の本番環境で下記のようなWebDriver managerのエラーが発生し、Google Chromeが起動しませんでした。
====== WebDriver manager ======
# 省略
selenium.common.exceptions.WebDriverException: Message: unknown error: Chrome failed to start: crashed.
(unknown error: DevToolsActivePort file doesn't exist)
(The process started from chrome location /usr/bin/google-chrome is no longer running, so ChromeDriver is assuming that Chrome has crashed.)以下のようにコードを書き換えることで、エラーが解消されWebDriverが起動しました。
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)以下のオプションを追加で解決
- options.add_argument("--headless") ブラウザを立ち上げないヘッドレスモードで起動
- options.add_argument("--no-sandbox") root権限の場合はChromeを起動することができないためサンドボックスの無効化オプションを付与する。ローカルで動かす場合は不要。
CentOS上で下記コマンドでGoogle Chromeを起動させてみると分かりますが、エラーが出てroot権限ではGoogle Chrome は動きません。
$ google-chrome
Running as root without --no-sandbox is not supported. See https://crbug.com/638180.root権限の管理者の場合は、サンドボックスの無効化オプションを付与し実行する必要があります。
以上で、一休の口コミのスクレイピングの実装が完成です。

